大数据深度学习的新利器:快速神经网络训练:P-network
ITRIZS 2020-03-25
Boris Zlotin;
国际TRIZ学会/TRIZS创始人(TRIZ五级大师)
Ideation; Progress Inc. 技术副总裁
Ivan Nehrishnyi, Sr; Ivan Nehrishnyi, Jr; & Vladimir Proseanic
Progress Inc.技术专家
姜台林 博士
法思诺创新学院 院长
国际TRIZ学会/ITRIZS 副主席 (TRIZ五级大师)
国际设计思考学会/ISDT 联合创始人 (DT大师)
1.P-network的理论基础
人工神经网络(ANN)于1969年在学术上被称为通用逼近设备[1]。
于此同时,学者也揭示了ANN的主要限制。众所周知,ANN中的每个突触具有一个突触权重。神经网络训练是通过对训练图像进行权重的计算和校正来实现的。对于每一个接下来的训练图像,必须再次校正相同的权重。因此,训练是通过大量的迭代进行的。随着训练量的增加,训练时间则呈现倍数的增长。
在参考文献[2]和[3]中,提出了一种新的神经网络设计方法,它不同于现有的神经网络,它的特点是每个神经突触都有多个校正权重,校正权重由一个特殊的装置(分配器)根据输入信号的值进行选择。
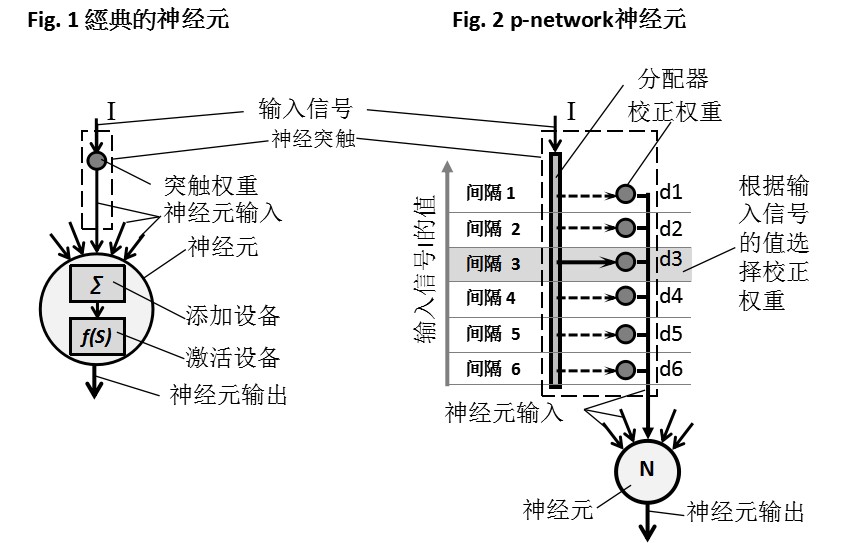
图1展示了一个众所周知的人工形式神经元,它包括一个求和装置和一个启动装置,图2展示了一个新的人工神经元,称为p神经元。在p神经元中,来自输入设备的信号被发送到分配器,分配器估算信号的值,将它引用到一个值区间中,并相应地为这个信号分配一个校正权重。
图2显示,一个值与值间隔3对应的信号应选择校正权值d3。
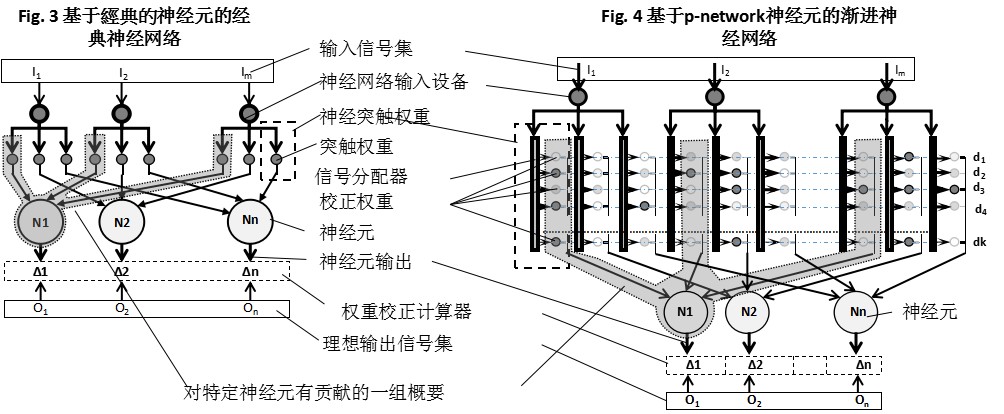
一个新的神经网络有一个经典的神经结构,p神经元被用来代替正式的神经元。图3展示了具有经典形式神经元的ANN,图4展示了具有本研究所提出的p神经元的p- network。
2.P-network的训练
如图4所示,P-network训练与经典ANN的训练有着显着性的差异。由于每个突触存在多个校正权重,因此不同的输入信号会启动不同的权重。相同值的输入信号启动相同的权重。
P-network的训练包括以下步骤:
1.输入信号被发送到分配器,
分配器根据输入信号的值启动突触处的权重,
通过其他输入信号,突触上的其他权重被启动,
同时这些权重的值将发送到与突触相连的神经元。
2.神经元的输出信号是由神经元接收到的校正权值的总和所给定的
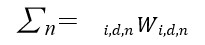
注释:
∑n-神经元输入信号;
i -校正权输入指针,确定信号输入;
d -校正权值区间指针,确定给定信号的值区间;
n -校正权神经元指数,确定接收到信号的神经元;
W i,d,n-校正重量值;
3.将接收到的神经元输出信号与预先设定的理想输出信号进行比较,生成校正信号,
用于校正权重的分组校正。其中,组校正是与给定神经元相关的启动校正权重的修正,
每个权重都改变为相同的值或乘以相同的系数。
以下是组校正信号的形成和使用的两种典型的非限制性变式:
变式#1 -根据理想输出信号与得到的输出信号总和之间的差值,形成和应用校正信号,如下所示:
根据公式计算各校正权重贡献到神经元n的相等校正值∆n:
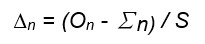
注释:
On -与神经元输出总和相对应的理想输出信号
∑n;
S -连接到神经元n的突触数。
变式2-基于所需输出信号与获得的输出总和之比的校正信号的形成和应用如下:
根据公式计算各校正权重反映到神经元n的相等校正值∆n:
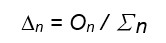
4.矫正所有连接到给定神经元的权值。根据第一个变式,Δn被添加到当前的重量值。在第二个变式,
当前重量乘以Δn价值。这就消除了给定神经元当前图像的训练误差。换句话说,不是传统的梯度下降法神经网络需要大量的迭代,P-network在一步中提供了对权重的根本校正。
5.重复步骤2到5,这样就完成了第一个训练阶段。可以通过其与下一阶段图像的训练来校正在第一阶段图像进行网络训练期间获得的校正后的权重,
如果在第一个训练阶段后没有达到预期的精度,可以再进行几个阶段的训练。
P-network计算重量修正的简单方法不需要迭代过程,提供了一个快速的完成训练阶段。对整个训练误差量的所有主动权重进行一步校正,大大减少了训练所需的时间间隔。
3.P-network的软件实现
本文的P-network已经使用面向对象语言(OOL)以软件形式实现。图5表示统一建模语言(UML)中P-network的软件实现:
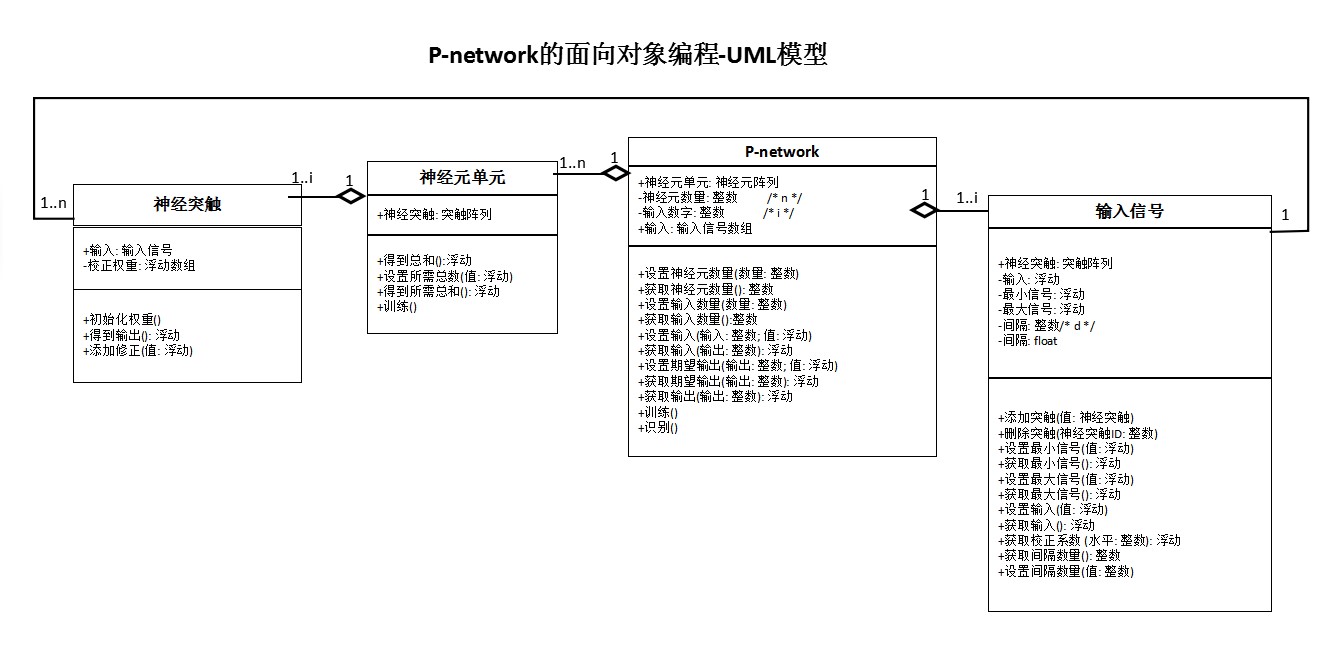
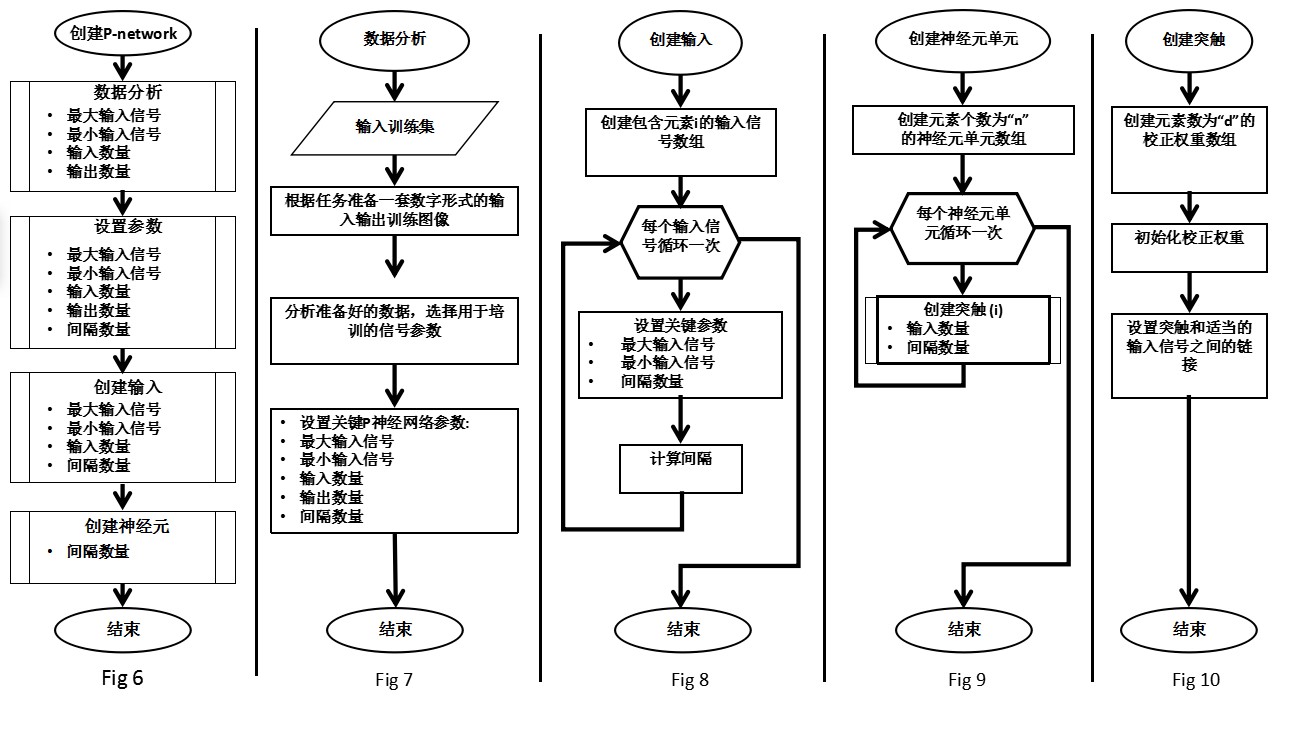
图5中的UML模型显示了生成的软件对象及其关系,以及这些对象的功能和参数。更详细的步骤如图6 - 12所示,包括:
•Fig.6 - P-network形成的一般顺序;
•Fig.7 -分析过程,为P-network的形成准备必要的资料;
•Fig.8 -输入信号处理,使P-network能够在其训练和操作期间与输入数据进行交互;
•Fig.9 -神经元单元的形成,包括具有矫正权重的神经元和突触,提供P-network训练和操作;
•Fig.10 -创建正确的突触权重。
在这个过程中,形成了以下几类对象:
•P-network
•输入信号;
•神经元单元;
•神经突触.
形成的神经元单元包括:
•神经突触类的对象数组;
•神经元: 一个变量,在培训过程中提供了”加”的功能;
•计算器: 一个变量,其中包含了预期总和的值,并在其中进行训练校正的计算。
神经元单元提供网络培训,包括:
•神经元总和的形成;
•预期价值的分配;
•更正的计算;
•在校正权重中引入校正的功能。
形成的对象类突触包括:
•校正权重
•指向与突触相关的输入的指示。
突触类提供以下功能:
•开始校正;
•因子乘以权重;
•权重校正。
形成的对象输入信号类包括:
•指向与给定输入连接的突触的指示数组;
•在输入信号的值所在的位置可变;
•潜在的最小和最大输入信号值;
•间隔数;
•间隔的宽度。
输入信号类提供以下功能:
•网络结构的形成,包括:
在输入和突触之间添加和删除连结;
给定输入的突触间隔数的分配。
•分配最小和最大输入信号的参数值;
•对网络运营的贡献:
设置输入信号;
设置校正系数。
形成的对象类P-network包括对象类数组:
•神经元单元;
•输入信号。
在培训过程中形成操作循环,其中:
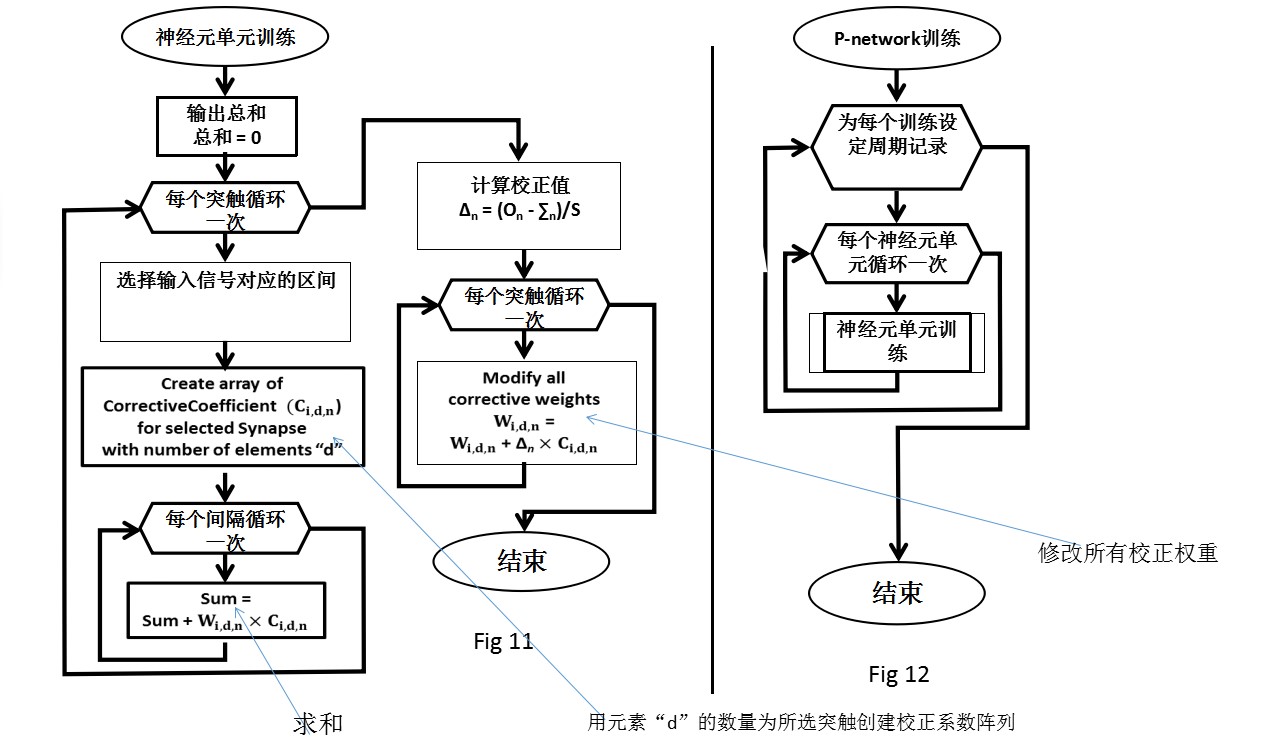
•神经元单元;
•神经元的输出就形成了它在周期开始之前等于零。对所有参与给定神经元单元的突触进行综述,其中每个突触:
分配器根据输入信号形成一组校正因子。
所有到达这个突触的重量都被检查,每一个重量都执行以下操作:
-乘法的重量值对应的系数Сi, d n;
-乘法的结果加到神经元的输出和上。
•计算校正值∆n;
•乘法的结果修正价值系数∆n, Сid n计算(∆n×Сi, d, n);
•对所有参与给定神经元单元的突触进行综述,其中每个突触:对所有传入突触的权重进行复核,每个权重由相应的修正值改变。
分别为:
图11 -单个神经单元的详细训练过程。
图12 - P-network训练的一般流程。
4.测试结果
本研究也根据上述算法构建的P-network在Python中进行测试。
对基于高级谷歌Tensor Flow技术的深度学习神经网络(DNN)与P-network进行了比较。基于标准统计IRIS检验的比较结果如下:
•训练误差:P-network的表现可与DNN的最佳结果相媲美;
•训练速度:P-network速度至少是DNN的3000倍。
•测试结果如下面的屏幕截图所示:
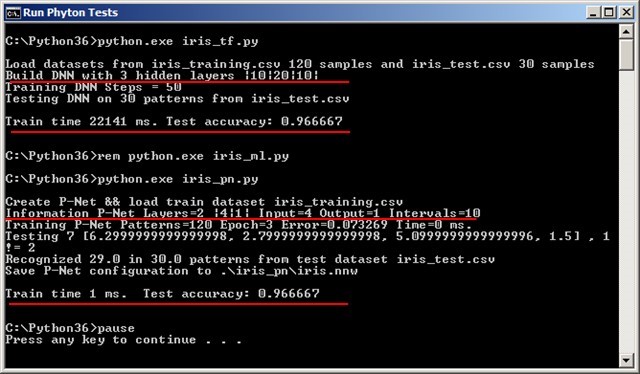
可以看出,在同样的精度下,P-network的训练速度为1 ms,而DNN为22141 ms。
测试比较结果是在以下的系统设备中进行:
5.结论
这些测试通过消除迭代计算的需要,证实了从根本上加速网络培训的理论预期。他们还发现了额外的好处:
•在预先定义的准确性要求下,网络训练周期的数量急剧减少。在某些情况下,整个训练在2-3个周期内完成,在某些情况下,会在几十个周期内完成,这进一步减少了训练时间。
•P-network不需要传统神经网络所需要的启动函数,删除此功能进一步提高了训练速度。
•P-network和所提出的训练方法可以显着加速各种专用神经网络的运行,例如霍普菲尔德和科荷伦神经网络,波尔兹曼机器和自适应网络。该网络及其训练方法可用于识别,聚类和分类,预测,关联信息搜索等,并可实时增加部分网络训练。
此外,P-network应用也可以:
•通过使用基于P-network的计算块和缓存内存系统,提高计算机的计算能力。
•节省计算资源,减少能源消耗。
•创建高性能、快速和可靠的大型数据库。
参考文献
- Marvin Minsky and Seymour Papert “Perceptrons: an introduction to computational geometry”, Cambridge, MA: MIT Press., 1969.
- D. Pescianschi, A. Boudichevskaia, B. Zlotin, and V. Proseanic, “Analog and Digital Modeling of a Scalable Neural Network,” CSREA Press, US 2015.
- Patent US 9390373.
- Patent US 9619749.
- Patent application US 20170177998 A1.
- International patent application PCT/US2015/19236, 06-Mar-2015.
- International patent application PCT/US2017/36758, 09-JUN-2017.